Natural Language Processing
1. Text Classification
juga dikenal sebagai categorization, yaitu diberi teks dari beberapa jenis, memutuskan mana dari satu set standar dari kelas itu milik. Identifikasi Bahasa dan klasifikasi genre adalah contoh dari klasifikasi teks, seperti analisis sentimen (mengklasifikasikan film atau produk review sebagai positif atau negatif) dan deteksi spam (mengelompokkan pesan email sebagai spam atau tidak-spam).
Salah satu contoh pemanfaatan teks mining adalah text categorization yaitu proses pengelompokan dokumen, yang dalam tugas akhir ini adalah konten web page, ke dalam beberapa kelas yang telah ditentukan. Jika tidak ada overlap antar kelas, yaitu setiap dokumen hanya dikelompokan kedalam satu kelas maka text categorization ini disebut single label text categorization. Text categorization bertujuan untuk menemukan model dalam mengkategorisasikan teks natural language. Model tersebut akan digunakan untuk menentukan kelas dari suatu dokumen.
Cara lain untuk berpikir tentang klasifikasi adalah sebagai masalah dalam kompresi data. Sebuah algoritma kompresi lossless mengambil urutan simbol, mendeteksi pola-pola berulang di dalamnya, dan menulis deskripsi dari urutan yang lebih kompak daripada yang asli.
Misalnya, teks “0,142857142857142857” mungkin dikompresi ke Compression algoritma bekerja dengan membangun kamus subsequences teks, dan kemudian mengacu pada entri dalam kamus. Contoh di sini hanya satu entri kamus, “142.857.”
Akibatnya, algoritma kompresi menciptakan sebuah model bahasa. Algoritma LZW khususnya langsung model distribusi probabilitas maksimum entropi. Untuk melakukan klasifikasi dengan kompresi, pertama-tama kita bersabar bersama-sama semua pesan pelatihan spam dan kompres mereka sebagai
Beberapa metode text categorization yang sering dipakai antara lain : k- Nearest Neighbor, Naïve Bayes, Support Vektor Machine, Decision Tree, Neural Networks, Boosting. Dalam pengaplikasian text categorization terdapat beberapa tahap, yaitu : preprocessing, training phase dan testing phase.
– Preprocessing
Tahap pertama dalam text categorization adalah dokumen preprocessing adalah :
1. Ekstrasi Term
Ekstrasi term dilakukan untuk menentukan kumpulan term yang mendeskripsikan dokumen. Kumpulan dokumen di parsing untuk menghasilkan daftar term yang ada pada seluruh dokumen. Daftar term yang dihasilkan disaring dengan membuang tanda baca, angka, simbol dan stopwords. Dalam tugas akhir ini akan dibahas juga mengenai pengaruh stopwords removal terhadap hasil klasifikasi. Berikut ini merupakan penjelasan singkat mengenai stopwords.
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti artikel dan preposisi yang hampir selalu muncul pada dokumen teks. Biasanya kata-kata ini tidak memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari informasi. Kata-kata tersebut (misalnya a, an, dan on pada bahasa Inggris) disebut sebagai Stopwords.
Sebuah sistem Text Retrieval biasanya disertai dengan sebuah Stoplist. Stoplist berisi sekumpulan kata yang ‘tidak relevan’, namun sering sekali muncul dalam sebuah dokumen. Dengan kata lain Stoplist berisi sekumpulan Stopwords.
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang ‘tidak relevan’ pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan Stoplist yang ada.
2. Seleksi Term
Jumlah term yang dihasilkan pada feature ekstrasi dapat menjadi suatu data yang berdimensi cukup besar. Karena dimensi dari ruang feature merupakan bag-of-words hasil pemisahan kata dari dokumennya. Untuk itu perlu dilakukan feature selection untuk mengurangi jumlah dimensi.
3. Representasi Dokumen
Supaya teks natural language dapat digunakan sebagai inputan untuk metode klasifikasi maka teks natural language diubah kedalam representasi vektor. Dokumen direpresentasikan sebagai vektor dari bobot term, dimana setiap term menggambarkan informasi khusus tentang suatu dokumen. Pembobotan dilakukan dengan melakukan perhitungan TFIDF. Term beserta bobotnya kemudian disusun dalam bentuk matrik.
– Training Phase
Tahap kedua dari text categorization adalah training. Pada tahap ini system akan membangun model yang berfungsi untuk menentukan kelas dari dokumen yang belum diketahui kelasnya. Tahap ini menggunakan data yang telah diketahui kelasnya (data training) yang kemudian akan dibentuk model yang direpresantasikan melalui data statistik berupa mean dan standar deviasi masing-masing term pada setiap kelas.
– Testing Phase
Tahap terakhir adalah tahap pengujian yang akan memberikan kelas pada data testing dengan menggunakan model yang telah dibangun pada tahap training. Tujuan dilakukan testing adalah untuk mengetahui performansi dari model yang telah dibentuk. Dengan beberapa parameter pengukuran yaitu akurasi, precision, recall, dan f-measure.
– Pembobotan
Vector space model merepresentasikan dokumen dengan term yang memiliki bobot. Bobot tersebut menyatakan kepentingan/kontribusi term terhadap suatu dokumen dan kumpulan dokumen. Kepentingan suatu kata dalam dokumen dapat dilihat dari frekuensi kemunculannya terhadap dokumen. Biasanya term yang berbeda memiliki frekuensi yang berbeda. Dibawah ini terdapat beberapa metode pembobotan :
1. Term Frequency
Term frequency merupakan metode yang paling sederhana dalam membobotkan setiap term. Setiap term diasumsikan memiliki kepentingan yang proporsional terhadap jumlah kemunculan term pada dokumen. Bobot dari term t pada dokumen d yaitu :
TF(d,t) = f (d, t)
Dimana f(d,t) adalah frekuensi kemunculan term t pada dokumen d
2. Inverse Document Frequency (IDF)
Bila term frequency memperhatiakan kemunculan term didalam dokumen, maka IDF memperhatikan kemunculan term pada kumpulan dokumen. Latar belakang pembobotan ini adalah term yang jarang muncul pada kumpulan dokumen sangat bernilai. Kepentingan tiap term diasumsikan memilki proporsi yang berkebalikan dengan jumlah dokumen yang mengandung term. Faktor IDF dari term t yaitu :
IDF(t) = log( n / df(t) )
Dimana N adalah jumlah seluruh dokumen, df(t) jumlah dokumen yang mengandung term t.
3. TFIDF
Perkalian antara term frequency dan IDF dapat menghasilkan performansi yang lebih baik. Kombinasi bobot dari term t pada dokumen d yaitu :
TDIF(d,t) = TF(d,t) x IDF(t)
Term yang sering muncul pada dokumen tapi jarang muncul pada kumpulan dokumen memberikan nilai bobot yang tinggi. TFIDF akan meningkat dengan jumlah kemunculan term pada dokumen dan berkurang dengan jumlah term yang muncul pada dokumen.
2. Information Retrieval
tugas mencari dokumen yang relevan dengan kebutuhan pengguna untuk informasi. Contoh yang paling terkenal dari sistem temu kembali informasi adalah mesin pencari di World Wide Web. Seorang pengguna Web dapat mengetik query seperti [ AI ke mesin pencari dan melihat daftar halaman yang relevan. Pada bagian ini, kita akan melihat bagaimana sistem tersebut dibangun. Sebuah pencarian informasi ( selanjutnya IR ) sistem dapat dicirikan oleh :
Sebuah korpus dokumen. Setiap sistem harus memutuskan apa yang ingin memperlakukan sebagai dokumen : sebuah paragraf, halaman, atau teks multipage.
Pertanyaan yang diajukan dalam bahasa query. Sebuah query menentukan apa yang pengguna ingin tahu. Bahasa query dapat hanya daftar kata, seperti [ buku AI ] ; atau dapat menentukan kalimat dari kata-kata yang harus berdekatan. Sebuah hasil set. Ini subset dari dokumen yang hakim sistem IR untuk menjadi relevan dengan query. Oleh relevan -, kita berarti mungkin berguna bagi orang yang berpose query, untuk informasi tertentu perlu dinyatakan dalam query -.
Presentasi hasil set. Ini dapat yang sederhana seperti daftar peringkat judul dokumen atau serumit warna peta berputar dari hasil set diproyeksikan ke ruang tiga – dimensi, diberikan sebagai tampilan dua dimensi.
– Information Retrieval = searching information
– Mencari informasi seperti dokumen berdasarkan permintaan (input pengguna) untuk mendapatkan informasi yang dibutuhkan pengguna dari semua dokumen.
Misalnya adalah mencari informasi dengan search engine di Dunia Wide Web (www), misalnya Google.
Karakteristik Information Retrieval
1. Sebuah kumpulan tulisan (document). Sistem harus menentukan mana yang ingin dianggap sebagai dokumen (paper). Contoh: sebuah paragraf, halaman, dll
2. User Query
Query adalah formula yang digunakan untuk mencari informasi yang dibutuhkan oleh pengguna. Dalam bentuk yang paling sederhana, sebuah query adalah kata kunci dan dokumen yang mengandung kata kunci adalah dokumen yang dicari
Contoh: [AI book]; [“Al book”]; [AI AND book];
[AI NEAR book] [AI book site:www.aaai.org].
3. Set of Results
Hasil dari query. Sebuah bagian dari dokumen yang relevan dengan query.
4. Display of result sets
Bisa daftar hasil di peringkat dokumen judul.
Awalnya, sistem bekerja Information Retrieval menggunakan Model Boolean. Tapi sekarang sebagian besar ditinggalkan.
Model Information Retrieval ada tiga jenis, yaitu :
• Model Boolean : merupakan model IR sederhana yang berdasarkan atas teori himpunan dan aljabar boolean
• Model Vector Space : merupakan model IR yang merepresentasikan dokumen dan query dalam bentuk vektor dimensional
• Model Probabilistic : merupakan model IR yang menggunakan framework probabilistik
Model ruang vektor dan model probabilistik adalah model yang menggunakan pembobotan kata dan perangkingan dokumen. Hasil retrieval yang didapat dari model-model ini adalah dokumen terangking yang dianggap paling relevan terhadap query.
Dalam model ruang vektor, dokumen dan query direpresentasikan sebagai vektor dalam dalam ruang vektor yang disusun dalam indeks term, kemudian dimodelkan dengan persamaan geometri. Sedangkan model probabilistik membuat asumsi-asumsi distribusi term dalam dokumen relevan dan tidak relevan dalam orde estimasi kemungkinan relevansi suatu dokumen terhadap suatu query.
3. HITS Algorithm
HITS (Hyperlink-Induced Topic Search)
Hal ini hampir sama dengan algoritma PageRank, tapi HITS tidak menghitung jumlah link di halaman, tapi melihat-lihat link ditemukan, jika sesuai dengan tujuan link, kata-kata yang lebih tepat antara link asal ke link tujuan, semakin tinggi nilai otoritas halaman.
Hyperlink-Induced Topic Search Kleinberg memberikan gagasan baru tentang hubungan antara hubs dan authorities. Dalam algoritma HITS, setiap simpul (situs) p diberi bobot hub (xp) dan bobot authority (yp) melalui operasi
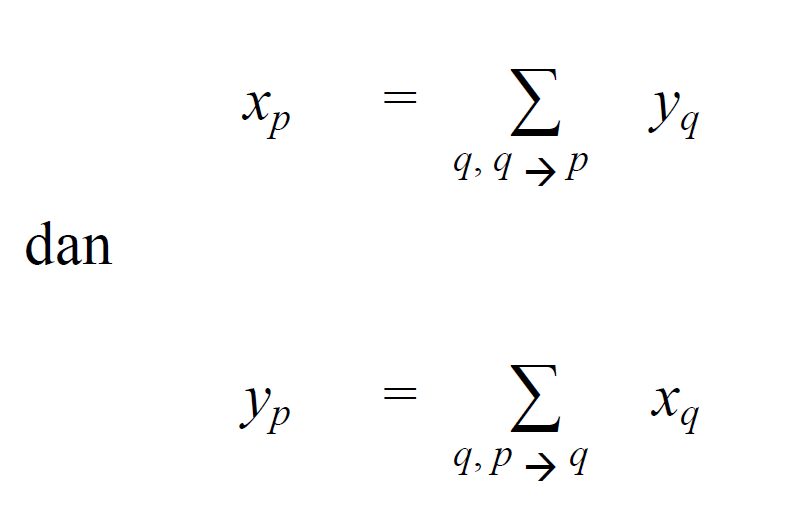
yang dalam hal ini nilai xp diperoleh dari jumlah seluruh nilai yq di mana q adalah situs-situs yang menunjuk (mengandung hyperlink) ke situs p (notasi q p menunjukkan bahwa q menunjuk ke p). Sementara nilai yp diperoleh dari jumlah seluruh nilai xq. Dari operasi tersebut, dapat dilihat bahwa antara hubs dan authorities terdapat sebuah hubungan yang saling memperkuat satu sama lain, yaitu: sebuah hub yang bagus menunjuk ke banyak authorities yang juga bagus, sementara sebuah authority yang bagus ditunjuk oleh banyak hubs yang juga bagus.
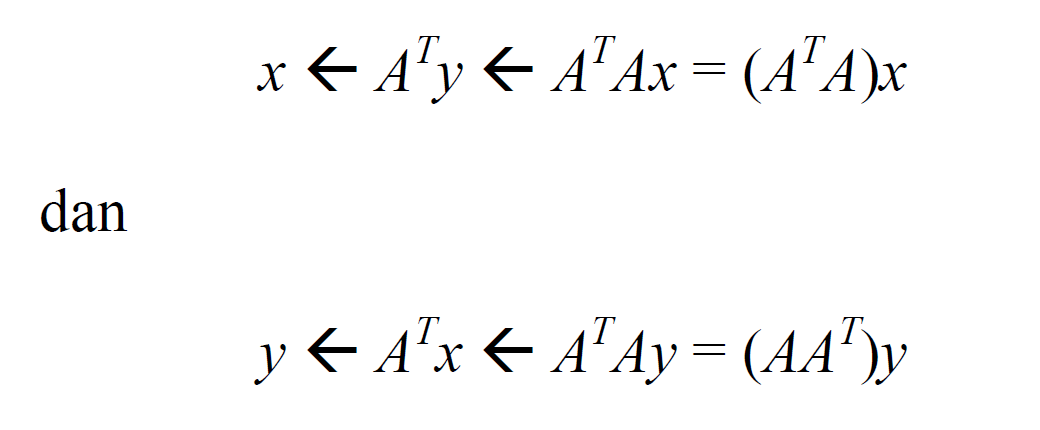
Untuk melakukan update secara berkala dari nilai-nilai tersebut, terdapat cara yang lebih singkat dibanding dengan melakukan perhitungan ulang dari rumus yang telah dibahas sebelumnya. Pertama-tama, nomori situs-situs hasil pencarian dengan angka {1,2,…,n} dan tentukan matriks ketetanggaan A yang berukuran n x n dari situs-situs tersebut. Lalu, himpun seluruh nilai x dalam sebuah vektor x = (x1,x2,…,xn) , lakukan hal yang serupa pada seluruh nilai y. Selanjutnya, update nilai x dan y dapat dilakukan melalui operasi
Di bawah ini adalah gambaran keseluruhan dari algoritma HITS.
langkah 1: Kumpulkan sejumlah r situs hasil pencarian sebuah topik yang terletak paling atas (highest-ranked) dari sebuah search engine. Sejumlah r situs ini dikumpulkan dalam sebuah himpunan akar (root) R.
langkah 2: Buatlah sebuah himpunan basis (base) S yang berukuran n, dengan cara memperbesar himpunan R (yaitu, menambah anggota himpunan dengan semua situs yang ditunjuk oleh situs-situs di R dan paling banyak sejumlah d situs tambahan tersebut menunjuk ke situs-situs di R).
langkah 3: Buatlah graf G[S] yang dihasilkan oleh situs-situs pada himpunan S sebagai simpul. Terdapat dua jenis links dalam graf G[S] ini, yaitu: transverse links (links antara situs-situs yang alamat domainnya berbeda) dan intrinsic links (links antara situs-situs yang berdomain sama). Semua sisi yang terbentuk dari intrinsic links dihapus dari graf G[S], sehingga yang tersisa hanyalah sisi-sisi dari transverse links.
langkah 4: Buat matriks ketetanggaan A yang berukuran n x n dan juga matriks transposnya AT. Normalisasikan vektor eigen ε1 dari ATA yang bersesuaian dengan nilai eigen λ1 terbesar.
langkah 5: Temukan elemen-elemen dengan nilai absolut dari hasil normalisasi vektor eigen yang besar. Kemudian, definisikan elemen-elemen tersebut sebagain authorities.
Pada akhirnya, algoritma HITS ini menghasilkan sebuah daftar singkat yang terdiri dari situs-situs dengan bobot hub terbesar serta situs-situs dengan bobot authority terbesar. Yang menarik dari algoritma HITS adalah: setelah memanfaatkan kata kunci (topik yang dicari) untuk membuat himpunan akar (root) R, algoritma ini selanjutnya sama sekali tidak mempedulikan isi tekstual dari situs-situs hasil pencarian tersebut. Dengan kata lain, HITS murni merupakan sebuah algoritma berbasis link setelah himpunan akar terbentuk. Walaupun demikian, secara mengejutkan HITS memberikan hasil pencarian yang baik untuk banyak kata kunci. Sebagai contoh, ketika dites dengan kata kunci ”search engine”, lima authorities terbaik yang dihasilkan oleh algoritma HITS adalah Yahoo!, Lycos, AltaVista, Magellan, dan Excite − padahal tidak satupun dari situs-situs tersebut mengandung kata ”search engine”.
4. Prolog
Sejarah Prolog
Prolog merupakan singkatan dari “Programing In Logic” pertama kali dikembangkan oleh Alain Colmetrouer dan P.Roussel di Universitas Marseilles Prancis tahun 1972. Selama tahun 70an, prolog populer di Eropa untuk aplikasi AI. Sedangkan di Amerika Serikat, para peneliti juga mengembangkan bahasa lain untuk aplikasi yang sama yaitu LISP. LISP mempunyai kelebihan dibandingkan prolog , tetapi LISP lebih sulit dipelajari.
Pada awalnya, Prolog dan LISP sangat lambat dalam eksekusi program dan memakan memori yang besar sehingga hanya kalangan tertentu yang menggunakannya. Dengan adanya Compiler Prolog, kecepatan eksekusi program dapat ditingkatkan, namun Prolog masih dipandang sebagai bahasa yang terbatas (hanya digunakan di kalangan perguruan tinggi dan riset).
Pandangan tersebut tiba-tiba berubah di tahun 1981 pada konverensi internasional I dalam sistem generasi kelima di Tokyo, Jepang. Jepang yang saat itu mengalami kesulitan bersaing dalam pemasaran komputer dengan Amerika Serikat, mencanangkan rencana pengembangan teknologi hardware dan software untuk tahun 1990an. Dan bahasa yang dipilih adalah Prolog.
Sejak saat itu, banyak orang menaruh minat pada prolog dan saat itu telah dikembangkan versi prolog yang mempunyai kecepatan dan kemampuan yang lebih tinggi, lebih murah dan lebih mudah digunakan, baik untuk komputer mainframe maupun komputer pribadi sehingga Prolog menjadi alat yang penting dalam program aplikasi kecerdasan buatan (AI) dan pengembangan sistem pakar (expert sistem).
Perbedaan Prolog dengan Bahasa Pemrograman Lainnya
Hampir semua bahasa pemrograman yang ada pada saat ini seperti Pascal, C, Fortran, disebutprocedural language untuk menggunakan bahasa tersebut diperlukan algoritma atau prosedur yang dibuat untuk menyelesaikan masalah. Program dapat menjalankan prosedur yang sama berulang-ulang dengan data masukkan yang berbeda-beda. Prosedur serta pengendalian program sepenuhnya ditentukan oleh programmer dan perhitungan yang dilakukan sesuai dengan prosedur yang telah dibuat. Dengan kata lain, Pemrograman harus memberi tahu komputer bagaimana komputer harus menyelesaikan masalah.
Prolog mempunyai sifat-sifat yang berbeda dengan bahasa yang disebutkan diatas, prolog disebut sebagai object oriented language atau declarative language. Dalam prolog tidak terdapat prosedur, tapi hanya tampilan data-data object (fakta) yang akan diolah dengan relasi antar object tersebut yang membentuk suatu aturan. Aturan-aturan ini disebut heuristik dan diperlukan dalam mencari suatu jawaban, dengan kata lain, prolog dalam prolog adalah database.
Pemrogram menentukan tujuan (Goal) dan komputer akan menentukan bagaimana cara mencapai tujuan tersebut serta mencari jawabannya. Caranya dengan menggunakan “Formal Reasoning” yaitu membuktikan cocok tidaknya tujuan dengan data-data yang telah ada dan relasinya. Prolog memecahkan masalah seperti yang dilakukan oleh pikiran manusia.
Dengan demikian, Prolog sangat ideal untuk memecahkan masalah yang tidak terstruktur dan yang procedure pemecahannya tidak diketahui, khusunya untuk memecahkan masalah non numeric.
Keampuhan Prolog
Terletak pada kemampuannya dalam mengambil kesimpulan (jawaban) dari data-data yang ada. Karena program dalam bahasa prolog tidak memerlukan prosedur (algoritma). Prolog sangat ideal untuk memecahkan masalah yang tidak terstruktur dan yang prosedur pemecahannya tidak diketahui, khususnya untuk memecahkan masalah non numerik.
Misalnya, dalam pembuatan program catur dengan prolog untuk menentukkan gerakan catur anda tidak perlu menganalisis semua kemungkinan atau menentukkan suatu prosedur tertentu untuk untuk menentukan gerakan berikutnya. Tetapi anda cukup menuliskan aturan umum permainan catur dan lebih baik lagi jika ditambah dengan aturan yang diperoleh dari pengalaman. Prolog akan menentukan sendiri langkah yang akan diambil berdasarkan data-data yang ada saat itu dan aturan-aturan yang diberikan.
Aplikasi Prolog
Prolog digunakan khususnya dibidang kecerdasan buatan (Artificial Intelegent) meliputi bidang:
1. Sistem Pakar (Expert System)
adalah program yang menggunakan teknik pengambilan kesimpulan dari data-data yang didapat seperti yang dilakukan oleh seorang ahli dalam memecahkan masalah. sebagai contoh program mendiagnosa penyakit. Pemakai menentukan tujuan (goal) yaitu penyakit yang diderita, untuk mendapatkan jawaban, program akan memberi pertanyaan yang harus dijawab oleh pemakai program.
2. Pengolahan bahasa alami (Natural Language Processing)
Natural Language Processing adalah program yang dibuat agar pemakai dapat berkomunikasi dengan komputer dalam bahasa manusia sehari-hari. Sebagai contoh adalah Lotus HAL, yaitu program Bantu untuk Lotus 1-2-3 agar dapat menerima perintah bahasa inggris seperti bahasa biasa. Program pengolahan bahasa alami menggunakan teknik AI dalam analisis input bahasa yang dimasukan melalui keyboard, program tersebut berusaha mengidentifikasi sintak, semantik dan konteks yang terkandung dalam suatu kalimat agar bisa sampai pada kesimpulan untuk bisa memberikan jawaban.
3. Robotik
Dalam robotik, Prolog digunakan untuk mengolah data masukan yang berasal dari sensor dan mengambil keputusan untuk menentukan gerakan yang harus dilakukan. Apalagi kalau robot menemukan peristiwa yang tidak diharapkan atau situasi yang berbeda.
4. Pengenalan Pola (Pattern Recognition)
Pengenalan pola banyak diterapkan dalam bidang robotik dan pengolahan citra (image processing). Misalkan, bagaimana komputer dapat membedakan gambar sebuah benda dan gambar benda yang lain, atau sebuah obyek yang berada diatas obyek lain.





