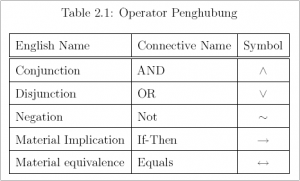
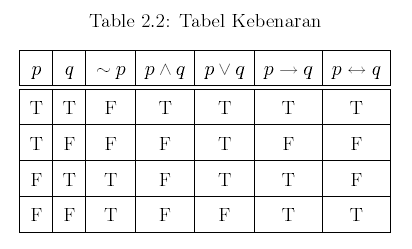
Jaringan Saraf Tiruan (Artificial Neural Network) merupakan salah satu sistem pemrosesan informasi yang didesain dengan menirukan cara kerja otak manusia dalam menyelesaikan suatu masalah dengan melakukan proses belajar melalui perubahan bobot sinapsisnya. Jaringan saraf tiruan mampu melakukan pengenalan kegiatan berbasis data masa lalu. Data masa lalu akan dipelajari oleh jaringan saraf tiruan sehingga mempunyai kemampuan untuk memberikan keputusan terhadap data yang belum pernah dipelajari. Selain itu jaringan saraf tiruan merupakan suatu metode komputasi yang meniru sistem jaringan saraf biologi.
Metode ini menggunakan ini elemen perhitungan non-linear dasar yang disebut neuron yang diorganisasikan sebagai jaringan yang saling berhubungan, sehingga mirip dengan jaringan saraf manusia. Jaringan saraf tiruan dibentuk untuk memecahkan masalah tertentu seperti pengenalan pola klafikasi karena proses pembelajaran. Layaknya neuron biologi, jaringan saraf tiruan merupakan sistem yang bersifat “foult tolerant” dalam 2 hal. Pertama dapat mengenali sinyal input yang agak berbeda dari yang pernah diterima. Kedua tetap mampu bekerja meskipun beberapa neuronnya tidak mampu bekerja dengan baik. Jika sebuah neuron rusak, neuron yang lainnya dapat dilatih untuk menggantikan fungsi neuron yang rusak tersebut.
Jaringan saraf tiruan seperti manusia, belajar dari suatu contoh karena mempunyai karakteristik yang adaptif, yaitu dapat belajar dari data-data sebelumnya dan mengenal pola data yang selalu berubah. Selain itu, jaringan saraf tiruan merupakan sistem yang terprogram artinya semua keluaran atau kesimpulan yang ditarik oleh jaringan didasarkan pada pengalamannya selama mengikiuti proses pembelajaran/pelatihan. Hal yang ingin dicapai dengan melatih jaringan saraf tiruan adalah untuk mencapai keseimbangan antara kemampuan memorisasi dan generalisasi. Kemampuan memorisasi adalah kemampuan jaringan saraf tiruan unutk mengambil kembali secara sempurna sebuah pola yang dipelajari. Sedangkan kemampuan generalisasi merupakan kemampuan jaringan saraf tiruan untuk menghasilkan respons yang bisa diterima terhadap pola-pola input yang serupa (namun tidak identik) dengan pola-pola yanhg sebelumnya telah dipelajari. Hal ini sangat bermanfaat bila pada suatu saat ke dalam jarinagn saraf tiruan itu diinputkan informasi baru yang belum pernah dipelajari, maka jarinagn saraf tiruan itu masih akan tetap dapat memberikan tanggapan yang baik, memberikan keluaran yang paling mendekati.
Cara pembelajaran atau pelatihan jaringan saraf tiruan dikelompokkan menjadi beberapa bagian, 2 diantaranya supervised learning dan unsupervised learning.
A. SUPERVISED LEARNING
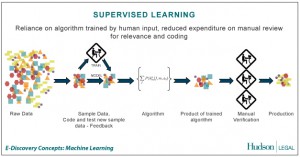
Supervised learning merupakan suatu pembelajaran yang terawasi dimana jika output yang diharapkan telah diketahui sebelumnya. Biasanya pembelajaran ini dilakukan dengan menggunakan data yang telah ada. Pada metode ini, setiap pola yang diberikan kedalam jaringan saraf tiruan telah diketahui outputnya. Satu pola input akan diberikan ke satu neuron pada lapisan input. Pola ini akan dirambatkan di sepanjang jaringan syaraf hingga sampai ke neuron pada lapisan output. Lapisan output ini akan membangkitkan pola output yang nantinya akan dicocokkan dengan pola output targetnya. Nah, apabila terjadi perbedaan antara pola output hasil pembelajaran dengan pola output target, maka akan muncul error. Dan apabila nilai error ini masih cukup besar, itu berarti masih perlu dilakukan pembelajaran yang lebih lanjut. Contoh algoritma jaringan saraf tiruan yang mernggunakan metode supervised learning adalah hebbian (hebb rule), perceptron, adaline, boltzman, hapfield, dan backpropagation.
Pada kesempatan ini saya akan membahas tentang metode hebb rule dan perceptron.
v Hebb rule merupakan metode pembelajaran dalam supervised yang paling sederhana, karena pada metoode ini pembelajaran dilakukan dengan cara memperbaiki nilai bobot sedemikian rupa sehingga jika ada 2 neuron yang terhubung, dan keduanya pada kondisi hidup (on) pada saat yang sama, maka bobot antara kedua dinaikkan. Apabila data dipresentasiakn secara bipolar, maka perbaikan bobotnya adalah
wi(baru)=wi(lama)+xi*y
Keterangan:
wi : bobot data input ke-i;
xi : input data ke-i;
y : output data.
Misalkan kita menggunakan pasangan vektor input (s) dan vektor output sebagai pasangan vektor yang akan dilatih. Sedangkan vektor yang hendak digunakan sebagai testing adalah vektor (x).
Algoritma pasangan vektor diatas adalah sebagai berikut:
0. Insialisasi semua bobot dimana:
wij=0;
i =1,2……n;
j =1,2…..m
1. Pada pasangan input-output(s-t), maka terlebih dahulu dilakukan langkah-langkah sebagai berikut:
a. Set input dengan nilai yang sama dengan vektor inputnya:
xi=si; (i=1,2……,n)
b. Set outputnya dengan nilai yang sam dengan vektor outputnya:
yj=tj; (j=1,2,…..,m)
c. Kemudian jika terjadi kesalahan maka perbaiki bobotnya:
wij(baru)=wij(lama)+xi*yj;
(i=1,2,….,n dan j=1,2,….,m)
sebagai catatan bahwa nilai bias selalu 1.
Contoh:
Sebagaimana yang kita ketahui dalam fungsi OR jika A & B= 0 maka “OR” 0, tetapi jika salah satunya adalah 1 maka “OR” 1, atau dengan kata lain jika angkanya berbeda maka hasilnya 1. Misalkan kita ingin membuat jaringan syaraf untuk melakukan pembelajaran terhadap fungsi OR dengan input dan target bipolar sebagai berikut:
Input Bias Target
-1 -1 1 -1
-1 1 1 1
1 -1 1 1
1 1 1 1
X= T= Bobot awal=
-1 -1 -1 w=
-1 1 1 0
1 -1 1 0
1 1 1 b=0
(catatan penting: bobot awal dan bobot bias kita set=0)
Data ke-1
w1 = 0+1=1
w2 =0+1=1
b =0-1=-1
Data ke-2
w1 = 1-1=0
w2 =1+1=2
b =0+1=1
Data ke-3
w1 = 0+1=1
w2 =2-1=1
b =0+1=1
Data ke-4
w1 = 1+1=2
w2 =1+1=2
b =1+1=2
Kita melakukan pengetesan terhadap salah satu data yang ada, misal kita ambil x=[-1-1] dan kita masukkan pada data ke-4 maka hasilnya adalah sebagai berikut:
y=2+(-1*2)+(-1*2)=-2
karena nilai yin=-2, maka y=f(yin)=f(-2)=-1 (cocok dengan output yang diberikan)
Perceptron merupakan salah satu bentuk jaringan syaraf tiruan yang sederhana. Perceptron biasanya digunakan untuk mengklasifikasikan suatu tipe pola tertentu yang sering dikenal dengan pemisahan secara linear. Pada dasarnya, perceptron pada jaringan syaraf dengan satu lapisan memiliki bobot yang bisa diatur dan suatu nilai ambang(thershold). Algoritma yang digunakan oleh aturan perceptron ini akan mengatur parameter-parameter bebasnya melalui proses pembelajaran. Nilai thershold( pada fungsi aktivasi adalah non negatif. Fungsi aktivasi ini dibuat sedemikian rupa sehingga terjadi pembatasan antara daerah positif dan daerah negatif.
Garis pemisah antara daerah positif dan daerah nol memiliki pertidaksamaan yaitu:
w1x1+ w2x2+b >
Sedangkan garis pemisah antara daerah negatif dengan daerah nol memiliki pertidaksamaan:
w1x1+ w2x2+b < –
Misalkan kita gunakan pasangan vektor input (s) dan vektor output (t) sebagai pasangan vektor yang akan dilatih.
Algoritmanya adalah:
0. Inisialisasi semua bobot dan bias:
(agar penyelesaiannya jadi lebih sederhana maka kita set semua bobot dan bias sama dengan nol).
Set learning rate( ): (0< 1).
1. Selama kondisi berhenti bernilai false. Lakukan langkah-langkah sebagai berikut:
(i) Untuk setiap pasangan pembelajaran s-t, maka:
a. Set input dengan nilai sama dengan vektor input:
xi=si;
b. Hitung respon untuk unit output:
yin=b+y-
c. Perbaiki bobot dan bias jika terjadi error:
jika y≠t maka:
wi(baru)=wi(lama)+
b(baru)=b(lama)+
jika tidak, maka:
wi(baru)= wi(lama)
b(baru)=b(lama)
Selanjutnya lakukan tes kondisi berhenti: jika tidak terjadi perubahan pada bobot pada (i) maka kondisi berhenti adalah TRUE, namun jika masih terjadi perubahan pada kondisi berhenti maka FALSE.
Nah, algoritma seperti diatas dapat digunakan baik untuk input biner maupun bipolar, dengan tertentu, dan bias yang dapat diatur. Pada algoritma tersebut bobot-bobot yang diperbaiki hanyalah bobot-bobot yang berhubungan dengan input yang aktif (xi≠0) dan bobot-bobot yang tidak menghasilkan nilai y yang benar.
Sebagai contoh, misalkan kita ingin membuat jaringan syaraf yang melakukan pembelajaran terhadap fungsi AND dengan input biner dan target bipolar sebagai berikut:
Input Bias Target
1 1 1 1
1 0 1 -1
0 1 1 -1
0 0 1 -1
Bobot awal : w=[0,0 0,0]
Bobot bias awal : b=[0,0]
Learning rate( ) : 0,8
Thershold(tetha) : 0,5
Epoh ke-1(siklus perubahan bobot ke-1)
Data ke-1
yin=0,0+0,0+0,0=0,0
Hasil aktivasi= 0(-0,5 < yin 0,5)
Target = -1
Bobot baru yang diperoleh:
w1= 0,8+0,8*-1,0*1,0=0,8
w2= 0,8+0,8*-1,0*1,0=0,0
Maka bobot bias barunya:
b= 0,8+0,8*-1,0=0,0
Data ke-3
yin=0,0+0,0+0,8=0,8
Hasil aktivasi= 1( yin > 0,5)
Target = -1
Bobot baru yang diperoleh:
w1= 0,0+0,8*1,0*0,0=0,0
w2= 0,8+0,8*-1,0*1,0=0,8
Maka bobot bias barunya:
b= 0,0+0,8*-1,0=-0,8
Data ke-4
yin=-0,8+0,0+0,0=-0,8
Hasil aktivasi= -1( yin 0,5)
Target = 1
Data ke-2
yin=-3,2+1,6+0,0=-1,6
Hasil aktivasi=-1(yin <-0,5)
Target = -1
Data ke-3
yin=-3,2+0,0+2,4=-0,8
Hasil aktivasi=-1(yin <-0,5)
Target = -1
Data ke-4
yin=-3,2+0,0+0,0=-3,2
Hasil aktivasi=-1(yin 0,5
Sedangkan garuis yang membatasi antara daerah negatif dan daerah nolnya memenuhi pertidaksamaan:
1,6×1+2,4×2-3,2 < – 0,5
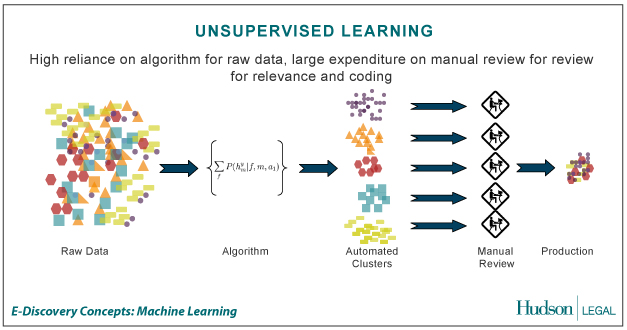
B. UNSUPERVISED LEARNING
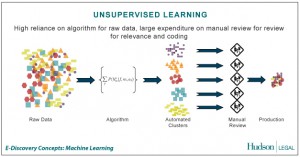
Unsupervised learning merupakan pembelajan yang tidak terawasi dimana tidak memerlukan target output. Pada metode ini tidak dapat ditentukan hasil seperti apa yang diharapkan selama proses pembelajaran, nilai bobot yang disusun dalam proses range tertentu tergantung pada nilai output yang diberikan. Tujuan metode uinsupervised learning ini agar kita dapat mengelompokkan unit-unit yang hampir sama dalam satu area tertentu. Pembelajaran ini biasanya sangat cocok untuk klasifikasi pola. Contoh algoritma jaringan saraf tiruan yang menggunakan metode unsupervised ini adalah competitive, hebbian, kohonen, LVQ(Learning Vector Quantization), neocognitron.
Pada kali ini saya akan membahas tentang metode kohonen. Jaringan syaraf self organizing, yang sering disebut juga topology preserving maps, yang mengansumsikan sebuah struktur topologi antar unit-unit cluster. Jaringan syaraf self organizing ini pertama kali diperkenalkan oleh Tuevo Kohonen dari University of Helsinki pada tahun 1981. Jaringan kohonen SOM(Self Organizing Map) merupakan salah satu model jaringan syaraf yang menggunakan metode pembelajaran unsupervised. Jaringan kohonen SOM terdiri dari 2 lapisan(layer), yaitu lapisan input dan lapisan output. Setiap neuron dalalm lapisan input terhubung dengan setiap neuron pada lapisan output. Setiap neuron dalam lapisan output merepresentasikan kelas dari input yang diberikan.
Penulisan istilah yang ada pada struktur jaringan kohonen Self Organizing Map adalah sebagai berikut:
X : vektor input pembelajaran.
X=(x1, x2,…, xj,…..,xn)
: learning rate
: radius neighborhood
X1 : neuron/node input
w0j : bias pada neuron output ke-j
Yj : neuron/node output ke-j
C : konstanta
Berikut ini adalah tahapan Algoritma dari kohonen self organizing map adalah sebagai berikut :
Langkah 1. Inisialisasikan bobot wij. Set parameter-parameter tetangga dan set parameter learning rate.
Langkah 2. Selama kondisi berhenti masih bernilai salah, kerjakan langkah-langkah berikut ini :
a. Untuk masing-masing vektor input x, lakukan :
Titik Pusat
(0,0) x,y
b. Untuk masing-masing j, lakukan perhitungan :
D(j)= )
c. Tentukan J sampai D( j) bernilai minimum.
d. Untuk masing-masing unit j dengan spesifikasi tetangga tertentu pada j dan untuk semua I, kerjakan :
wij(baru)=(wij)lama+ [xi –wij( lama)]
e. Perbaiki learning rate ( )
f. Kurangi radius tetangga pada waktu-waktu tertentu.
g. Tes kondisi berhenti.
Sebagai contohnya, data yang digunakan adalah penelitian berupa realisasi penerimaan keuangan daerah tingkat II suatu propinsi serta jumlah penduduk pertengahan tahunnya dalam sebuah kabupaten/kota. Atribut-atribut yang digunakan dalam penelitian ini adalah:
a. X1 = Jumlah penduduk
b. Pendapatan Daerah Sendiri(PDS) yang terdiri dari:
1. Pendapatan Asli Daerah(PDA) yang berupa:
ü X2 = Pajak Daerah
ü X3 = Retribusi Daerah
ü X4 = Bagian laba usaha daerah
ü X4 = Penerimaan lain-lain
2. Bagian pendapatan dari pemerintah dan instansi yang lebih tinggi yang berupa:
ü X6 = Bagi hasil pajak
ü X7 = Bagi hasil bukan pajak
ü X8 = Subsidi daerah otonom
ü X9 = Bantuan pembangunan
ü X10= Penerimaan lainnya
3. Pinjaman pemerintah daerah
ü X11= Pinjaman Pemerintah Pusat
ü X12= Pinjaman Lembaga Keuangan Dalam Negeri
ü X13= Pinjaman Dari Luar Negeri
Data set yang digunakan sebagai input tersebut dinormalkan dengan nilai rata-rata sebagai acuan yang analog dengan persamaan:
f(x)-
Berdasarkan data yang tesebut maka akan terlihat untuk masing-masing atribut memiliki nilai terendah, nilai tertinggi, dan nilai rata-rata. Selanjutnya dari nilai rata-rata tersebut maka akan menjadi acuan untuk menentukan input dari data menuju ke input pada jaringan saraf tiruan kohonen dengan pengkodean 1 dan 0. Kemudian data-data input tersebut akan diproses oleh JST sehingga menghasilkan output berupa kelompok daerah tingkat II berdasarkan penerimaan daerah. Jaringan kohonen SOM ini akan menghubungkan antara neuron input dan neuron output dengan koneksi bobot, yang mana bobot ini selalu diperbaiki pada proses iterasi pelatihan jaringan. Kemudian aliran informasi system JST ini akan mengelompokan tingkat kesejahteraan daerah tingkat II, diawali dengan dimasukkannya data penerimaan daerah. Data-data inilah yang akan berfungsi sebagai input awal selain parameter input berupa learning rate( ), dan radius neighborhood(R).
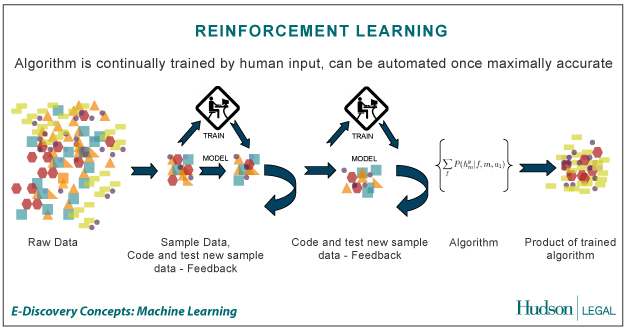
C. REINFORCEMENT LEARNING
Pembelajaran mesin metode reinforcement learning menjadi suatu pilihan dalam penentuan pengendalian robot. Metode ini mengasumsikan bahwa lingkungan terdefinisi sebagai himpunan keadaan (states) S dengan agen (robot) memiliki pilihan aksi A dengan jumlah tertentu. Untuk setiap langkah, yang didefinisikan sebagai pembagian waktu secara diskrit, agen melakukan pengamatan terhadap keadaan lingkungan, st ,dan memberikan keluaran berupa aksi, at.
Agen mendapatkan suatu reward, R yang menunjukkan kualitas aksi yang diberikan agen berdasarkan ekspektasi pemrogram. Agen kemudian melakukan observasi ulang terhadap lingkungannya, . Keadaan yang dituju dari metode pembelajaran ini ialah mendapatkan experience tuples (st, , , ), dan mendapatkan pembelajaran atas suatu pemetaan keadaan-keadaan untuk mengukur nilai jangka panjang pada keadaan tersebut. Pemetaan tersebut didefinisikan sebagai optimal value function.
Salah satu algoritma reinforcement learning yang dapat digunakan adalah Q-Learning.
Fungsi tersebut merepresentasikan nilai reward akibat agent mengambil aksi a dari keadaan s yang mengakibatkan perpindahan keadaan menjadi s’. Parameter merupakan discount factor sebagai ukuran terhadap reward yang pada proses berikutnya. Setelah mendapatkan Q-function yang optimal, terdapat pertimbangan optimasi p*(s) yang merupakan nilai maksimum dari suatu keadaan.
Nilai Q-function disimpan dalam suatu struktur tabel dalam indeks yang mengacu pada state dan action. Untuk setiap waktu robot menghasilkan aksi, experience tuple dihasilkan dan tabel untuk keadaan s dan aksi a.
Dalam pemrograman robot, implementasi reinforcement learning merupakan dukungan yang mempermudah hubungan aksi robot terhadap keadaan lingkungan. Suatu robot dapat memandang sebuah task sebagai fungsi reward yang lebih terbebas dari bias program dibandingkan melalui pemetaan kondisional.
Dalam penelitian ini, persoalan penentuan jalur merupakan suatu persoalan deterministik yang dapat dikategorikan sebagai exploration problem. Dalam hal ini, agent membutuhkan tahapan khusus untuk mempelajari lajurnya dan menyimpan informasi hasil pembelajarannya. Eksplorasi
yang dilakukan sebagai tahapan pembelajaran peta lajur dilakukan menggunakan strategi pencarian tertentu.
Strategi pencarian yang diimplementasikan dalam penyelesaian pencarian jalur pada penelitian ini menggunakan metode Greedy Best-First Search. Bentuk sederhana dalam metode ini adalah mencari pengambilan estimasi langkah terpendek menuju goal state. Fungsi yang menghitung estimasi tersebut dinamakan fungsi heuristik yang dilambangkan dengan h:
h(n) = estimasi langkah terpendek menuju goal
Dalam strategi ini, agent diprogram untuk mengambil keputusan berupa action dengan nilai reward tertentu. Nilai reward tersebut menjadi informasi bagi agent untuk memilih action yang mengakibatkan pengambilan langkah terdekat terhadap goal. Nilai tersebut didapatkan melalui reinforcement learning dan digunakan untuk diacu sebagai fungsi heuristik pada strategi pencarian Greedy Best-First Search.
Depth-First Search
Metode pencarian Depth-First Search (DFS) merupakan metode uninformed search. Hal ini menunjukkan bahwa pencarian melalui DFS dilakukan tanpa dukungan informasi nilai apapun, termasuk jumlah langkah menuju goal state. Dalam metode ini, agent hanya mampu membedakan state yang berkedudukan sebagai goal dan yang bukan (Russel, 1995).
Apabila dimodelkan melalui graf pohon pencarian, agent pada metode DFS melakukan pencarian yang terfokus pada kedalaman aras di setiap titiknya. Apabila agent sudah tidak bisa lagi mencari lebih dalam sedangkan ia berada pada state non-goal, agent akan melakukan backtracking menuju state pada aras lebih rendah. Agent yang melakukan bactracking melakukan pencarian melalui sisi yang belum dicari pada titik di aras yang lebih rendah. Ekspansi dilakukan hingga agent menemukan goal state.
Persoalan yang diselesaikan melalui pendekatan pembelajaran mesin reinforcement learning memiliki sejumlah keadaan yang tertentu (state) yang diperoleh berdasarkan aksi (action) yang dilakukan agent. Aksi yang dilakukan disertai dengan nilai reward tertentu bergantung pada pendekatan penyelesaian masalah. Melalui proses learning, agent berusaha mencari sejumlah aksi yang memberikan nilai reward maksimal hingga goal state tercapai dan agent menghentikan pencarian action. Proses learning yang dilakukan dapat disederhanakan sebagai entry nilai bagi tabel state-action-reward yang menjadi model yang dibangun sebagai acuan fungsi target dalam kondisi pengujian.
Dalam penerapan pembelajaran mesin menggunakan Q-learning, sebagaimana penjelasan pada dasar teori sebelumnya, terdapat suatu nilai Q yang merupakan reward akibat pengambilan suatu action dari state tertentu, dengan suatu nilai tambahan. Nilai ini didapat melalui pengalian suatu faktor secara rekursif terhadap rangkaian reward pada agent. Rangkaian reward tersebut mendapatkan referensi nilai terhadap immediate reward pada goal state.
Sebagaimana penjelasan sebelumnya, goal state bersifat absorptif sehingga eksplorasi yang mencapai state tersebut menghentikan eksplorasi agent.
Agent memiliki susunan informasi mengenai reward untuk setiap aksi dalam bentuk table entry yang diperbarui dalam setiap pembelajaran. Informasi mengenai reward untuk setiap action dalam state tertentu pada table entry ini diinisiasi dengan nilai nol. Pembaruan nilai mengacu pada fungsi Q (s,a) yang telah didefinisikan sebelumnya. Secara ilustrasi.
DECISION LEARNING TREE
Decision Tree Learning digunakan pada statistik, data mining, dan machine learning. Decision Tree Learning menggunakan Decision Tree sebagai model prediktif yang memetakan observasi sesuatu menjadi sebuah kesimpulan target nilai. Input dari Decision Tree Learning adalah data diskret dan outputnya berupa RULE (pohon pengetahuan)
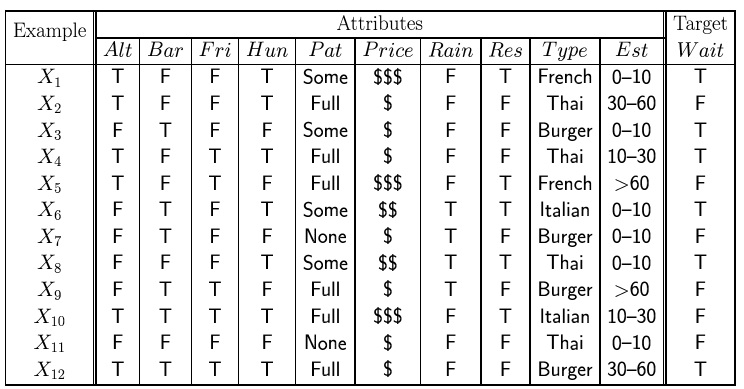
DATA SAMPLE
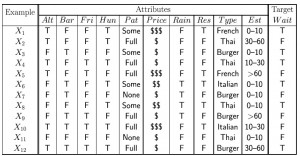
Ada 10 variabel yang digunakan untuk dasar mengambil keputusan. Kelas keputusan ada dua yakni Menunggu/Tidak di sebuah restoran
ALT : Alternate ; Bar : ada bar atau tidak ; FRI : Weekend ; Hun : Hungry ;PAT: pengunjung ; Price:harga ; RES: Reservation ; Type : tipe restoran ;EST: estimated time
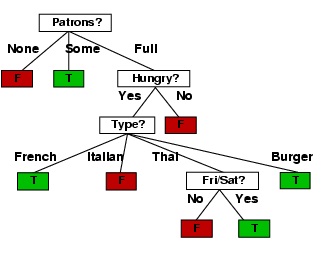
HASILNYA POHON KEPUTUSAN
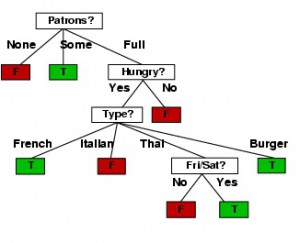
Kotak yang diarsir adalah daun . Kotak tanpa arsiran adalah akar atau cabang . Pola untuk mengubah menjadi RULE adalah
1) Akar/Cabang adalah proposisi pembentuk frase IF
2) Daun adalah proposisi pembentuk Frase THEN
Contoh
1) IF Patron = None THEN Wait = False
2) IF Patron = Full and Hungry = Yes and Type = French Then wait = true
3) IF Patron = Full and Hungry = Yes and Type = Thai and Fri/Sat = yes Then wait = true
dst